分子对接的最初思想起源于 Fisher.E 提出的酶与底物相互作用的“锁和钥匙模型",它指的是底物和酶(也就是分子对接中的配体和受体)之间通过几何匹配和能量匹配而相互识别的过程,也就是说分子之间的相互作用不仅是指参与对接两个分子在空间构象上的相互匹配,还要满足能量的匹配。即要求配体和受体间需要存在空间结构、氢键作用、静电作疏水作用等方面的互补匹配,这也就是所谓的互补匹配原则。根据对接分子对接配体、受体的体系大小和对体系简化程度的不同,分子对接方法可以分为三类:
1.刚性对接:刚性对接方法在计算过程中,参与对接的分子构象不发生变化,仅改变分子的空间位置与姿态,刚性对接方法的简化程度最高,计算量相对较小,适合于处理大分子之间的对接。
2.半柔性对接:半柔性对接方法允许对接过程中小分子构像发生一定程度的变化,但通常会固定大分子的构像,另外小分子构像的调整也可能受到一定程度的限制,如固定某些非关键部位的键长、键角等,半柔性对接方法兼顾计算量与模型的预测能力,是应用比较广泛的对接方法之一。之后介绍的 Autodock 系列对接软件使用的便是半柔性对接的方法。
3.柔性对接:柔性对接方法在对接过程中允许研究体系的构象发生自由变化,由于变量随着体系的原子数呈几何级数增长,因此柔性对接方法的计算量非常大,消耗计算机时很多,适合精确考察分子间识别情况。
但是幸运的是,目前已经存在了各种各样的分子对接软件如 Dock,Autodock,FlexX 和Affinity 等来实现我们的对接过程。而我们用户只需要做简单的准备工作和后续的分析工作即可。
项目整体流程图如下:
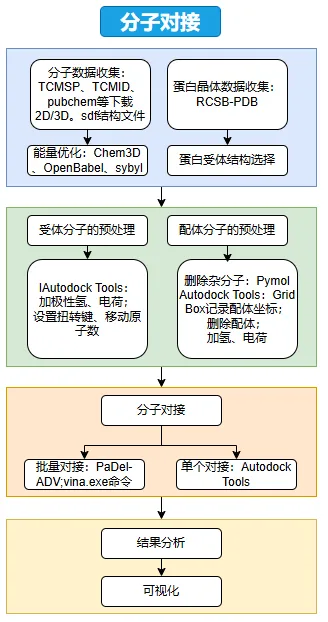
二、核心应用领域
分子对接技术就像是给锁(蛋白质靶点)和钥匙(候选小分子)提供虚拟的“试配”平台,在计算机上模拟它们如何结合并计算结合强度。它的应用领域很广,操作流程也已相当成熟。
1.药物发现与开发(最核心领域)
1)虚拟筛选:从百万级化合物库中快速筛选出潜在活性分子,取代高通量筛选,大幅降低成本和时间。
2)先导化合物优化:对初筛出的苗头化合物进行结构修饰以提高活性,解释不同分子活性差异原因,指导理性设计。
3)药物重定位:探索已上市药物或临床候选物的新靶点,发现老药新用途
4)作用机制阐释:解析药物与靶点精确结合模式,为新药研发提供分子水平证据。
2.食品与营养健康
1)功能成分验证:预测蓝莓花青素、大豆异黄酮等活性成分如何与体内关键酶或受体互作,验证其抗氧化、抗衰老等功效。
2)活性肽挖掘:筛选和设计具有降血压、抗菌等活性的生物肽,预测其与靶点结合能力。
3)酶机理研究:研究食品加工中关键酶与底物互作机制,为改善酶特性提供指导。
3.其他前沿拓展
1)农药创制:针对害虫特有靶点,设计高效、低毒的绿色农药。
2)蛋白质工程:设计具有特定功能的人工蛋白质或酶。
3)生物修复:筛选或设计能高效结合并降解环境污染物的酶。
4)分子机制探究:揭示病毒蛋白如何入侵细胞(如新冠病毒与ACE2受体结合)等基础生物学问题。
功能 | 数据库/软件 | 作用 |
成分收集 | TCMSP、TCMID等分子数据库, | 中药/研究成分收集 |
成分结构下载 | Pubchem | 提供配体的结构信息 |
靶点预测 | TCMSP、SwissTarget、靶点计算工具等 | 提供受体的结构信息 |
成分结构能量最小化 | Chem3D 20.0、 OpenBabel、sybyl等 | 通过调整分子构象使体系达到局部能量最低点。这一过程对于后续的虚拟筛选、分子对接等研究至关重要,可以消除初始结构中不合理的高能构象,提高计算结果的可靠性。 |
配体、受体批量对接 | Autodock Vina | http://vina.scripps.edu/ 说明:这里既有软件的下载,也有软件的教程以及运行Vina的一些软件,请自行探索 |
这个软件中包含了Autodock Tools | MGLTools | http://mgltools.scripps.edu/downloads 说明:这个软件中包含了AutoDockTools |
分子坐标和格子参数准备 | Autodock Tools | 蛋白晶体对接前处理及分子坐标和格子参数准备 |
Autodock Vina的GUI(图形界面) | PaDEL-ADV | http://www.yapcwsoft.com/dd/padeladv/ 说明1:这个是运行Vina的GUI即是图形界面,因为单独的Vina只能命令行运行,因此为了方便采用图形界面 说明2:PaDEL-ADV是一个Java程序,需要提前按照好Java的JRE环境 |
蛋白受体文件准备 | PDB、Uniprot数据库 | 提供受体的结构特征 |
互作分析(3D) | Pymol、PLIP | 用于对配体和受体结构进行3D互作分析可视化 |
互作分析(2D) | LigPlot+-、PoseView Web、PoseView | 用于对配体和受体结构进行2D互作分析可视化 |
4.1. 分子对接精简流程
1)受体、配体分子坐标文件准备:
①受体分子(通常是蛋白质)去除溶剂分子、杂分子,加极性氢,加电荷
②从头绘制配体分子,加极性氢,加电荷,设置分子柔性等。
2)格子参数的准备:格子(Grid)就是分子对接中用户指定的受体和配体可能发生相互作用的一个长方体区域,我们要在进行分子对接开始之前指定这个区域的位置和大小。
3)分子对接:准备好的分子坐标文件和格子参数文件输入对接程序,运行后给出配体分子对接的构象,分析预测能量
4)结果分析:配体分子相似构象聚类分析、配体分子构象可视化分析、配体分子同受体分子相互作用可视化分析、AutoGrid 计算的亲和势能等。
4.2. 软件准备
我们所要使用的分子对接软件主要是 Autodock 系列对接软件中的 Autodock Vina,它是继 Scripps 实验室的 Autodock 4 对接程序之后由 Oleg Trott 等人推出的使用新的打分函数、预测准确率更高并支持并行化的更高效易用的对接程序。它的使用方法和 Autodock 4 类似,只是少了调用 AutoGrid 程序(原 Autodock 4 中需要用到)这一步。
在准备输入给对接程序的分子坐标和格子参数时,我们需要使用的是 Autodock Tools, 它是和 Autodock 4 以及 Autodock Vina 配套使用的有用户图形界面的一个程序,同时在分析对接结果时,我们也会用到它。
更重要的是,我们需要一个 Linux 环境,来运行最后虚拟筛选部分涉及到的 Shell 脚本。
4.3. 配体和受体基础数据收集
4.3.1. 分子数据收集
1)中药分子收集:基于TCMSP、TCMID等中药数据库,下载需要进行对接的分子,根据分子的名称在Pubchem、NCBI PubCompound网站下载相应的3D.sdf结构文件并进保存1_MOL文件夹。
2)单分子直接在Pubchem网站下载相应的3D.sdf结构文件并保存。
3)使用 Gaussview 从头画出配体的空间结构模型保存为 mol2 文件,稍微复杂的分子在画完后需要做一下量子化学水平的结构优化。
4)如果配体十分复杂,可以先使用 ChemDraw 或 ChemBioDraw 画出配体结构的平面图,保存成 cdx 后缀的文件,然后使用 OpenBabel 转换成 mol2 文件。
4.3.2. 分子结构能量优化
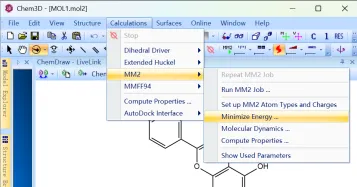
1)少量分子:使用Chem3D 20.0打开,Calculations>MM2>Minimize Energy>Run>save as,保存能量优化后的结构进行后续对接。
2)批量分子:使用OpenBabel、sybyl进行批量能量优化。
4.3.3. 蛋白晶体数据收集
4.3.3.1蛋白晶体结构的选择
首先,我们需要了解一下RCSB-PDB数据库,这个数据库是目前世界上最大的蛋白晶体结构存储数据库。在这个数据库上,我们能找到不同物种的蛋白的结构晶体信息,包括,蛋白晶体来源,蛋白信息,配体信息等等。我们基本能从这个网站上找到相关蛋白的信息。
蛋白受体文件从RCSB PDB网站检索,搜索基因如DPP4,得到不同来源的蛋白受体结构,结构选择原则:
① Homo sapiens来源;
② X-RAY DIFFRACTION Refinement Resolution (Å) 参数尽量小(分辨率);
③数据发布时间新;
④点击详情页下拉查看相关Gene Names是否一致。
下载选择好的蛋白晶体文件(Legacy PDB Format),并将下载好的文件进行命名:蛋白晶体名称_基因名称(为了更好识别,建议命名)例:5T4B_DPP4.pdb。
1)蛋白晶体结构的要求
对于我们后续用于对接的蛋白晶体结构,基本上有两个要求:蛋白具有配体小分子、蛋白结构完整。下面我们来详细的说明一下:
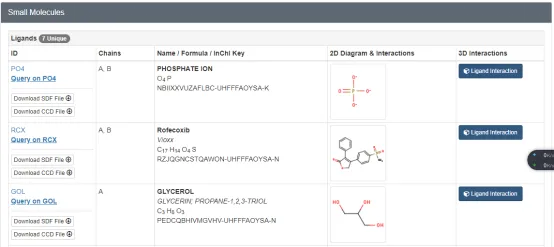
① 蛋白晶体结构中有对应的结合配体(大部分情况下是小分子,极少数是一段氨基酸链;注意对于配体分子的确定都是需要看原文献的,但我们可以通过PDB网站上的数据进行判断),具体如下:
我们一般可以在PDB数据库上一个具体的蛋白页面上看到如下信息,在这里列出了这个蛋白晶体文件中包含的配体信息:
但是,当配体小分子太多的时候,我们需要确定那个是与蛋白结合的小分子?
这个时候,我们可以结合PDB页面上的标题,或者阅读这个蛋白晶体文件对应的文章来确定配体小分子。
② 蛋白质配体周围大概12A(范围可以缩小)范围的蛋白结构不能出现断链,也就是说在这个范围内的氨基酸结构是完整的
③ 蛋白质要足够大:当出现靶点对应的蛋白在PDB中只是很小的一段,查看原文献,观察这个pdb是不是催化亚基,或者是膜外部分的等等。
2)蛋白晶体结构存在问题的处理方法
有时候,在寻找靶点对应的蛋白晶体结构的时候,我们会遇到一些情况,这个时候就需要我们进一步的处理。
① 蛋白没有配体:我们需要优先找有配体的蛋白结构,如果实在是没有的话就用无配体的蛋白结构,后期可以通过一些网站获得商业软件的功能自动寻找到蛋白可能的结合区,用于后续对接;
② 蛋白配体周围12A内有断链:我们需要优先找无断链的蛋白结构,如果实在是没有的话,采取同源模建补齐断链,具体我们可以这样操作:1)在SWISS-MODEL这个网站上,以断链的蛋白的PDB编号为模板,进行同源模建;2)下载建模的蛋白pdb文件,同PyMol打开建模的蛋白pdb文件和断链蛋白的pdb,对齐,选择断链蛋白的pdb的大部分残基,在断链区域选择建模的蛋白pdb的残基,然后保存。
③ 靶点无对应的蛋白三级结构:可用该靶点在其他物种中的蛋白结构为模板进行建模(相似度越高越好)。
4.3.3.2蛋白结构的处理(具体见4
.4.1.1)
选择好蛋白晶体文件后,我们需要对这个文件进行处理,一般情况下PyMOL就能很好的完成这些处理:
① 去掉重复结构(在蛋白晶体文件会出现重复序列结构,根据情况,决定是否去掉重复结构;这里提一下,对于一些二聚体,很多情况下我们是需要保留结构的);
② 去水分子;
③ 去配体周围小分子(注意这个要参考原文献,根据我的经验,对于HME这样的分子通常是保留的);
④ 金属离子(根据文献分析,是否保留;如果金属离子参与了配体与蛋白的结合,那就需要保留;一个并不一定正确的识别方法就是,你直接看金属离子是否在蛋白和配体的结合区)
4.3.3.3其它
在我们确定好了靶点之后,我们并不一定要在PDB数据库中搜索对应的晶体结构,我们可以去Uniprot数据库查找对应蛋白的3D结构信息,这里我们以人类PTGS2为例:
在这里我们可以看到以下信息:
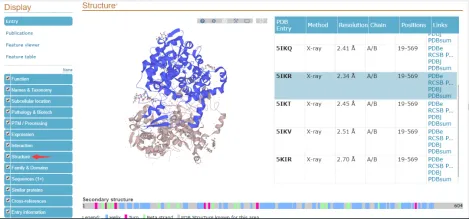
PDB Entry:PTGS2蛋白的晶体结构的PDB数据库编号,我们可以直接通过这个编号去PDB数据库查看详细信息
Method:PTGS2蛋白的晶体结构的获得方法:X-ray、NMR,我们常见的是X-ray
Resolution:PTGS2蛋白的晶体结构的分辨率,这个数值越小越好,在有多个候选蛋白,且基本信息一样的情况下,我们选择Resolution数值低的蛋白
Chain:PTGS2蛋白在晶体结构中位置,有时候一个蛋白晶体结构文件包含多个蛋白的信息,我们需要确定我们的目标蛋白所在链(通常一个链一个蛋白);以5IKR为例,PTGS2蛋白在A和B链上,至于这个是蛋白二聚体还是结构重复,需要大家去查看相关信息说明,其实它对应的文章就会有详细的说明。
Positions:PTGS2蛋白的晶体结构结晶出来的长度,以5IKR为例,这里PTGS2蛋白的19-569氨基酸获得了晶体结构。
4.4. 分子对接过程与结果分析(以单个配体为例)
4.4.1. Autodock Vina 预处理
在本教程中,我们研究的体系是依赖 NAD+的 蛋白脱乙酰酶 Sirtuin 3 及其抑制剂的相互作用情况。Jeremy S. Disch1 等人已在实验室中筛选出了几种具有高效抑制功能的小分子化合物,并且将其中的 3 种抑制剂进行了与 Sirtuin 3 蛋白的共结晶并解析了 其晶体结构存放于PDB 数据库中。
从 Jeremy S. Disch 等人的工作中,我们了解到,Sirtuin 3 起催化功能时,NAD+辅酶与底物会结合到底物结合槽部位,而抑制剂结合时,NAD+将不再结合,仅有抑制剂结合到底物结合部位附近。考虑到 Sirt 3 结合不同的抑制剂时,蛋白的构象差异远小于结合底物时的情况,故我们以 结合了抑制剂的结构(PDB:4JSR)出发,开始我们的研究。
4JSR 中除了 Sirt 3 蛋白和抑制剂 1NQ 之外,还存在一个金属 Zn 离子和很多水分子的氧原子,但是我们期望探究其他抑制剂和 Sirt 3 蛋白相互作用的情况,所以要把抑制剂 1NQ 替换成我们预定的抑制剂(文献中的第 17 号抑制剂)。(Disch JS et al.Discovery of thieno[3,2-d]pyrimidine-6-carboxamides as potent inhibitors of SIRT1, SIRT2, and SIRT3.J Med Chem. 2013 May 9;56(9):3666-79. )
基于上述信息,在进行Autodock对接前,我们需要对分子和蛋白进行处理,即对接体系(受体、配体)的确定与结构预处理。
4.4.1.1受体分子的预处理
1)初步处理:将在PDB数据库中下载的蛋白晶体PDB文件的蛋白用Pymol软件打开。
①点击右下角“S”,将蛋白序列调出。
② 红色序列为水分子、溶剂分子等杂分子需删除(选中右击remove),(① 这里需要确认蛋白结构里面是否有多肽等结构存在,如果存在,需要去PDB数据库中查看是否作为这个蛋白结构活动所必须的,如果不是必须的需要将其删除。如果选择的蛋白晶体中没有配体存在,需要将这个多肽作为配体对接的位置进行保留。除此之外,如果多肽离配体距离较近的话,意味着他会对受体和配体间的对接产生影响,则需要保留。② 如果存在二聚体或多聚体情况,我们需要去PDB数据库确认结构,如果四聚体的结构相似,则保留一个聚体,其余三个删掉,此外,同时检查蛋白的配体、底物等情况,建议搜索一下蛋白晶体的配体结构在蛋白中的作用都是什么,再考虑是否作为后续的对接位置坐标定位)
③ 进行保存,File-Export Molecule-Selection(处理后的蛋白名字)-Save-选择PDB格式保存。
2)Autodock Tools处理蛋白
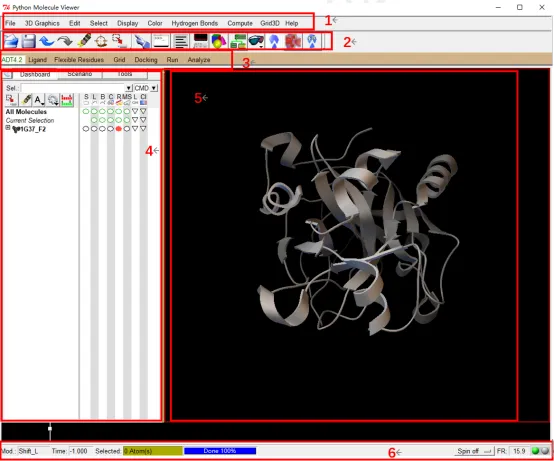
① 打开 Autodock Tools 界面,可以看到如图的界面:
Figure 1: Autodock Tools 界面:1 PMV 菜单; 2 PMV 工具栏; 3 ADT 菜单; 4 仪表板窗口部件; 5 分子显示窗口; 6 信息栏
进行如下操作:
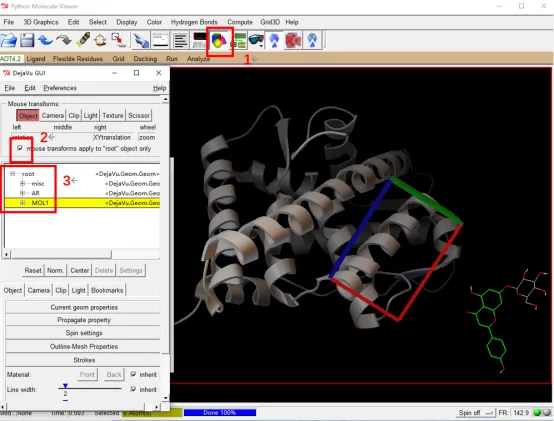
(1)点击进入 File → Read Molecule 选择“4JSR.pdb”,打开受体分子,选择 Ribbon 类型的representation 表现方式,并按链(by chain)着色,可以看到只有一个亚基(显示为A/B链的存在)。
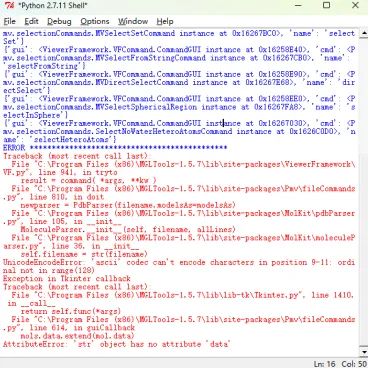
如出现以下问题,
从错误信息来看,问题主要源于文件路径 / 名称包含非 ASCII 字符(如中文、特殊符号等),导致老旧版本的 MGLTools(依赖 Python 2.x)在处理时出现编码错误,进而引发后续的属性错误。解决步骤如下(建议在C盘/D盘建一个文件夹,这个文件夹里是做分子对接的全部软件和所需的数据,相关全部路径用英文):将需要打开的 PDB 文件(或其他分子文件)移动到纯英文路径下)。文件名本身也需改为纯英文 / 数字 / 下划线,例如 ligand.pdb 而非 配体.pdb 或 my ligand.pdb。
(2)点击 Select → Select From String 打开 Select From String 对话框,在 Residue 框中输入先存配体名称 1NQ*(可打开PDB数据库查询该蛋白晶体,Small Molecules下的Ligands即为配体),点击 Add ,再点击 Dismiss 按钮关闭,新出现的黄色的部分就是自带的配体抑制剂 1NQ。
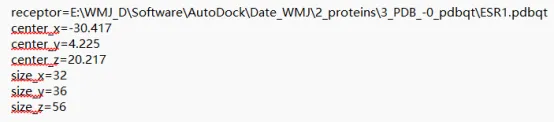
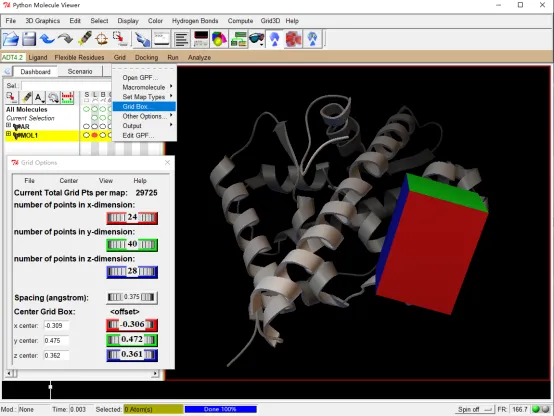
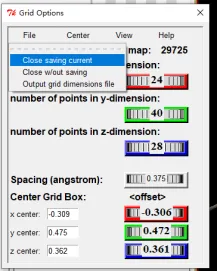
(3)点击 Grid →Grid Box →滑动 Center Grid Box 的三个坐标滚柱,移动格子,并通过上面的三个滚柱调节格子的大小将选择的黄色抑制剂完全包围(可调整配体的显示为棍状模式,再行包裹;如果看不到格子在哪里,就把结构缩小,进行旋转)。最终选择的中心坐标为:26.97、30.944、11.051,格子大小为 14 20 20,记下这些数值。点击关闭 Grid Options 框(建议新建一个记事本conf.txt保存在英文目录autodock文件夹里,将以上信息放在里面,后面用于批量对接)。
(4)删除配体:点击 Select → Select From String 打开 Select From String 对话框,在 Residue 框中输入1NQ,在 Atom 框中输入*(通配符,表示所有原子);点击 Add 选中所有杂分子(溶剂分子和抑制剂分子)。最后,点击 Dismiss 按钮关闭 Select From String 对话框,可以看到水分子和抑制剂都被选取了;点击 Edit → Delete → Delete Selected Atoms 删除已选择的分子,点击弹出的警告窗口上的 CONTINUE 按钮删除。
(5)加氢:点击 Edit → Hydrogens → Add 为受体分子加 H(X 射线衍射无法获 H 的坐标数据。)注意:加极性氢(连接在具有电负性的原子如 N、O、S 等上氢原子),并合并所有的非极性氢(连接在碳原子上的氢原子)点击 Edit → Hydrogens →Merge Non-Polar)。
(6)加电荷:点击 Edit → Charges → Add Kollman Charge 为受体分子加电荷。
(7)点击 Grid → Macromolecule → Choose,选择后保存修改过的受体分子,这里保存为F2.pdbqt(保存路径建议为纯英文路径,文件夹建议在蛋白晶体处理前文件夹的旁边,这里我取名为PDB_-0)。
4.4.1.2配体分子的预处理
进行如下操作:
1)点击 Ligand → Input → Open ... 在弹出的对话框中将文件类型由 PDBQT 改为mol2(pdb 格式的配体文件可能会在下一步出现问题),选择“ligand.mol2”,打开我们自己构建的抑制剂配体分子,为配体分子加上极性氢,加上电荷(方法同3.1.1)。
2)点击 Ligand → Torsion Tree → Detect Root… ADT 自动判定 Ligand 的 Root
3)点击 Ligand → Torsion Tree → Show Root Expansion显示 Root 扩展信息
4)点击 Ligand → Torsion Tree → Show/Hide Root Marker 显示/隐藏 Root 标记
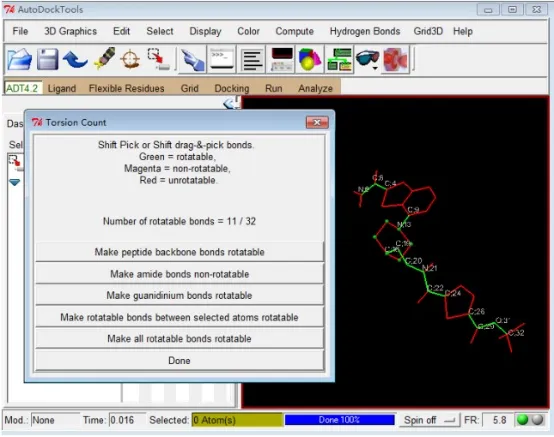
5)点击 Ligand → Torsion Tree → Choose Torsions… 选择 Ligand 中可扭转的键,弹出
6)Torsion Count 对话框中点击 Make all active bonds non-rotatable,Make rotatable bonds between selected atoms rotatable 以及 Make amide bonds rotatable。最后结果如下图所示:该 Ligand 分子 11 个键被设置成可扭转的键(rotatable,绿色),点击 Done 确定并关闭此对话框(注意:通常情况下,一般将环与环之间的单键设置为可旋转的)
7)点击 Ligand → Torsion Tree → Set Number of Torsions… 弹出 Set Number of Active Torsions 对话框,以设置可活动的键的数量,同时指定设定活动键时是需要移动最少的原子(fewest atoms)还是最多的原子(most atoms)。在这里我们设置 fewest atoms,数量为 6,点击 Dismiss 关闭对话框。
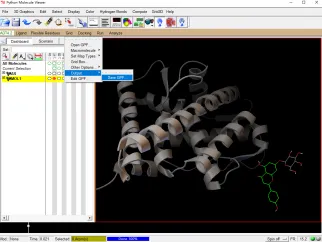
8)点击 Ligand → Output → Save as PDBQT… 将准备好的 Ligand 分子保存为“ligand.pdbqt”文件。
Figure 2: 第六步中Torsion Count 对话框及 Ligand 分子 Torsion 设置效果(绿色圆球表示 Root,绿色键表示可扭转,紫色表示非扭转,红色表示不可扭转)。
9)需要说明的是:OpenBabel可以快速批量将分子转化成pdbqt后缀的格式(代码处理会导致后续对接时分子出现问题,所以慎用)。
① 下载OpenBabel,并安装。
②sdf/mol2转化为pdbqt格式,同时加氢、设置旋转键。
打开存放小分子的文件夹,并在文件地址框里输入cmd,弹出命令行,输入以下代码:obabel *.mol2 -O *.pdbqt -h -c -xb。等待文件夹转化完成即可。
-h:代替使用Autodock Tool的加氢;-c :加电荷;-xb:代替了设置可旋转键的操作是否正确。
4.4.2Autodock Vina 对接
4.4.2.1 PaDEL-ADV运行对接(可批量对接)
PaDEL-ADV对接的相关操作如下:
1)首先准备好相关文件,其中Ligand文件夹中的是分子文件,可以是一个或者多个。
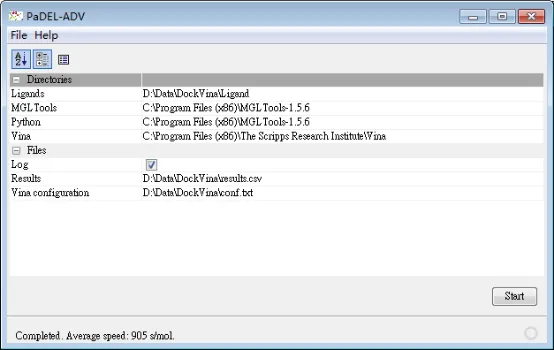
2)打开PaDEL-ADV,设置相关程序的位置:
① Ligands:分子文件所在位置
② MGLTools:这个软件所在位置
③ Python:这个Python程序的位置实际上和MGLTools位置相同,因为MGLTolls安装时自带了Python程序,版本2.5版本
④ Vina:Vina所在位置(通常C:\Program Files (x86)\The Scripps Research Institute\Vina)这个位置。-
⑤ Results:对接得分所在位置,时一个csv文件
⑥ Vina configuration:对接参数所在位置
PaDEL-ADV运行界面:
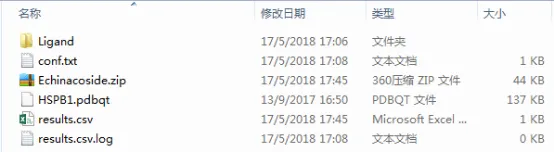
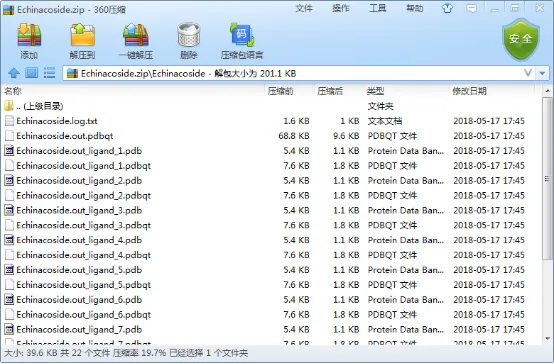
运行结束后,每一个分子都有一个压缩文件,里面包含了其具体结果
4)PaDEL-ADV注意事项
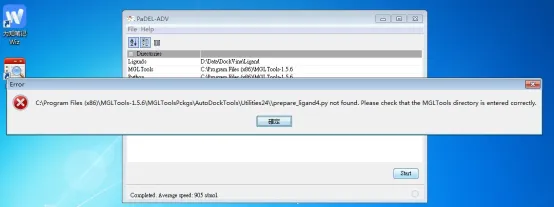
① 由于PaDEL-ADV版本和MGLTools版本存在差别,因此在运行时会出现如下所示的错误,这个错误是表明运行中没有发现运行所需的文件。
② 具体,我们可以按照上述错误,查看原始安装目录中的情况:
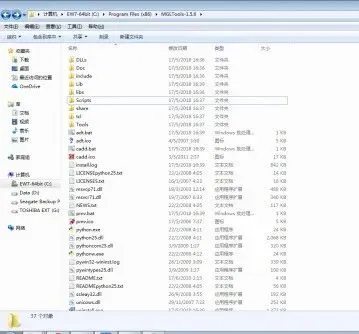
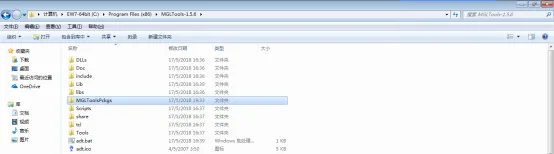
③ 我们发现,并没有MGLToolsPckgs这个文件夹,这是因为,随着版本的更新,最新的版本1.5.6中,MGLToolsPckgs下AutoDockTools被移到了其他目录中:C:\Program Files (x86)\MGLTools-1.5.6\Lib\site-packages
④ 因此,为了解决这个问题,我们需要在根目录下新建一个MGLToolsPckgs文件夹,并将AutoDockTools文件夹拷贝到MGLToolsPckgs目录下,这样程序就能顺利运行。
⑤在解决了上述的问题后,重新操作“PaDEL-ADV运行对接”就能在Windows上完成Autodock Vina的对接了。
4.4.2.2 vina.exe直接调用命令行进行对接
4.4.2.3 Autodock Tools实现单个配体和蛋白对接
首先我们要创建工作文件夹:选择一个磁盘新建autodock工作文件夹,将autodock安装文件复制到该工作文件夹,将mgltools安装文件中的adt.bat文件复制到工作文件夹。
此外,设置工作路径:打开AutoDock Tools,选择file-preferences-set设置工作路径为前面创建的工作文件夹。
1)将预处理好的分子和蛋白导入Autodock Tools中。选择grid-macromolecule-open打开预处理后保存的蛋白pdbqt文件,弹出的窗口点击YES。选择grid-set map types-open ligand打开预处理后保存的小分子pdbqt文件。
2)设置对接盒子:
①选择grid-grid box,在弹出的窗口中调节滚轮和spacing数值使盒子完全包裹住蛋白(盒子是蛋白上小分子的对接范围,若已知小分子与蛋白的结合区域可以调整对接盒子的大小和位置)
② 点击1处图标,在弹出的窗口中取消2处√,点击3处展开root选择小分子,在右边窗口中按住鼠标右键,滑动鼠标将小分子拖出对接盒子。勾选2处√,关闭此窗口。
③ 点击file-close saving current,然后点击grid-output-save GPF保存对接盒子为gpf文件。
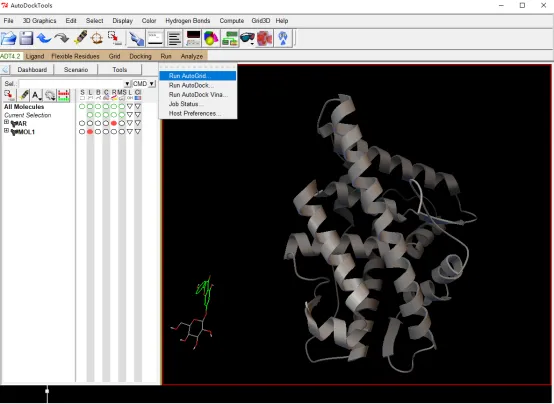
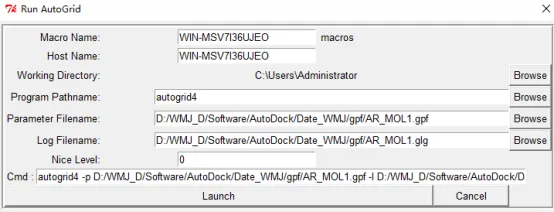
④ 点击run-run autogrid,在弹出的窗口红框里选择上一步保存的gpf文件,然后点击launch,之后会弹出一个运行窗口。等待运行完成窗口自动关闭。
3)运行对接盒子
① 设置对接参数:点击docking-macromolecule-set rigid filename选择pdbqt蛋白文件,点击docking-ligand-choose选择小分子点击接受。
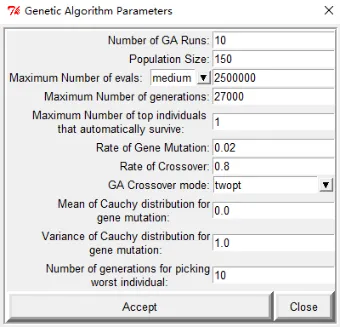
点击docking-search parameters-genetic algorithm,弹出的窗口是对接参数,第一个选项对接次数建议设置50次以上,其他参数按照默认设置,然后点击Accept。
点击docking-docking parameters弹出的窗口点击accept。最后点击docking-output-LamarkianGA(4.2)输出.dpf格式对接文件。
② 运行对接:点击edit-delect-delect all molecula,然后点击run-run autodock,在弹出的窗口Parameter Filename中选择上一步保存的dpf文件,点击Lunch就会开始运行对接,等待运行窗口关闭对接结束。
4)结果分析
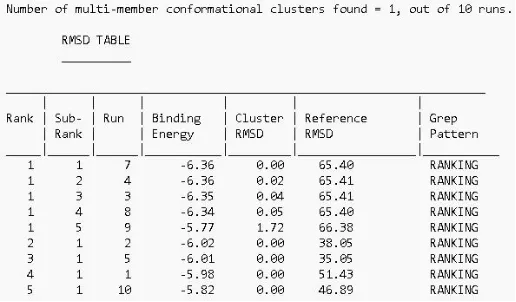
打开之前设置的autodock工作文件夹,其中有很多结构文件及中间运行文件,其中的.dlg文件为结果文件。打开结果文件,界面下方的RMSD表格即为对接结果。默认进行十次对接,每行为其中一次对接的结果,按结合能排序,选择排名第一的作为对接结果,记录其结合能数据。
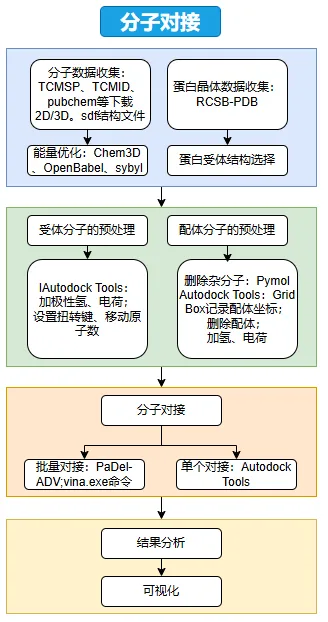
该流程贯通“数据收集-结构预处理-分子对接-结果分析-可视化”全链条。信息分析流程如下图:
以上为分子对接全教程的上半节内容(简介、软件列表及对接流程),下一期我们将为大家分享下半节内容,即结果分析和绘图,需要完整文档和直接对接服务可联系以下微信。【免责声明】MOL-Pi公众号为公益号,推送文章目的仅为学术交流使用,仅供读者参考,不构成具体建议在任何情况下,MOL-Pi团队不对任何人因使用本公众号中的任何内容所致的任何损失负任何责任。此外,本公众号所发布的所有文章,如有涉及他人知识版权等问题,请立即联系我们删除!MOL-Pi公众号中“原创”标识仅代表原创编译之作,不代表本平台对文本主张版权。版权归原作者所有!如需依托【MOL-Pi】公众号发布文章宣传,请予以联系!





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
